How Multi-Cloud Accelerates Software Delivery
Speed is often the first benefit DevOps teams notice when they start distributing workloads across providers. But the gains are not automatic. They come from deliberate architectural choices that align each piece of the delivery pipeline with the cloud environment where it runs most efficiently.
For example, a team might provision ephemeral testing environments, meaning short-lived environments created on demand and destroyed after use, on whichever provider offers the fastest spin-up time in a given region. That alone can shave minutes off every CI/CD cycle. Multiply that by dozens of deployments per day, and the cumulative time savings become significant.
Multi-cloud also supports delivery speed through:
-
Environment specialization: Staging on one cloud, production on another, each tuned for its purpose.
-
Parallel deployment pipelines: Pushing updates to multiple regions simultaneously using different providers.
-
Reduced bottlenecks: Avoiding single-provider rate limits or capacity constraints during peak deployment windows.
The key enabler here is automation. Without infrastructure as code (IaC), standardized CI/CD templates, and automated provisioning, managing multiple clouds would slow teams down rather than speed them up. Tools like Terraform, Pulumi, and cloud-agnostic Kubernetes configurations allow teams to define infrastructure once and deploy it consistently across providers.
Nearly half of all workloads and data now reside in the public cloud, which means the pipeline itself, not just the application, increasingly lives in multi-cloud territory. Teams that automate aggressively across those environments are the ones delivering faster.
For a step-by-step breakdown of building automated cloud pipelines, tech stacks, and hybrid DevOps workflows, see Tech-Driven DevOps: How Automation is Changing Deployment.
Multi-Cloud Deployment in Practice
A SaaS company serving both U.S. and European markets runs its production deployments on Azure in Europe for data residency compliance, while using AWS in North America for faster content delivery. Both environments are provisioned through the same Terraform modules, which means a single merge to the main branch triggers parallel, provider-specific deployments without manual intervention.
Building Resilience Through Distributed Cloud Operations
Speed matters, but so does reliability. One of the strongest arguments for multi-cloud in a DevOps context is resilience. When your entire operation depends on a single provider, any outage, whether regional or service-specific, can halt deployments and affect production traffic.
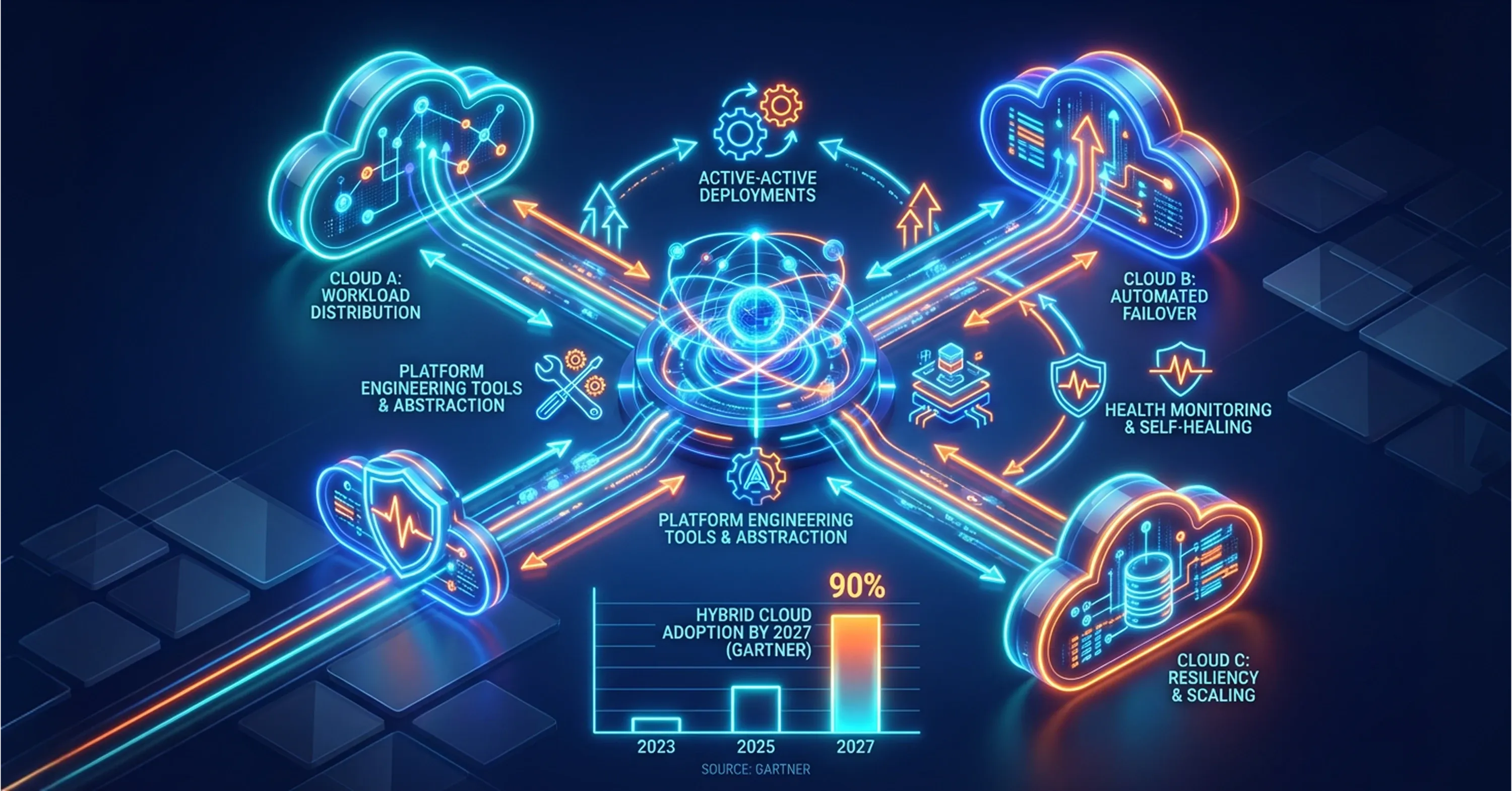
Distributing workloads across providers creates natural failover paths. If one cloud experiences degraded performance, traffic can shift to another without requiring a full disaster recovery event. This is not just theoretical. Teams that architect for multi-cloud resilience treat it as a core part of their deployment strategy, not an afterthought.
Effective resilience in a multi-cloud setup depends on several practices:
-
Active-active deployments: Running the same service on two or more clouds so traffic can be rerouted instantly.
-
Cross-cloud health monitoring: Using observability platforms that provide a unified view of performance across providers.
-
Automated failover logic: Defining policies that detect failures and redirect workloads without human intervention.
Gartner forecasts that 90% of organizations will adopt a hybrid cloud approach through 2027, and resilience is a major driver behind that trajectory. While hybrid cloud combines private and public infrastructure, multi-cloud goes further - distributing workloads across two or more public cloud providers to eliminate single points of failure and maximize deployment flexibility. For DevOps teams specifically, resilience is not just about uptime. It is about maintaining the ability to deploy continuously, even when parts of the infrastructure experience issues.
This is also where the relationship between DevOps and platform engineering becomes important. Platform teams increasingly build internal developer platforms that abstract provider-specific details, giving DevOps engineers a consistent interface for deploying to any cloud. That abstraction layer makes resilience patterns easier to implement and maintain.




