AI SREs: Refactoring Legacy Templates into Modern Modules
Large language models can already parse legacy ARM or CloudFormation into Terraform 1.8 HCL, reducing manual refactor time.
Practical workflow:
-
Feed the template and desired module style guide into the LLM
-
Validate generated code with terraform validate and policy checks
-
Run cost estimation and security scans before merging
This AI assistance aligns with Gartner analyst Paul Delory’s comment that developers should not need to know Terraform exists. By abstracting the heavy lifting, LLM copilots free engineers to focus on application logic.
A leading provider of managed IT services already wraps such LLM refactors into its onboarding service, letting enterprises modernize hundreds of templates in weeks rather than quarters.
Observability as Code Closes the Loop
Self-healing only works when the system sees itself. Observability as Code provisions metrics, logs, and traces in the same repo as infrastructure.
Steps to implement:
-
Create Terraform/Pulumi modules that instrument new services with OpenTelemetry
-
Auto-generate dashboards for every microservice
-
Treat alert thresholds as code, reviewed in pull requests
Benefits:
-
Consistent monitoring coverage
-
Drift detection for telemetry resources themselves
-
Faster Mean Time to Detect (MTTD) and Repair (MTTR)
For a deeper understanding of how observability and feedback loops drive resilient cloud operations, refer to Top Cloud Sources Every Business Should Know.
Observability as Code provides the signals that GitOps uses to drive remediation, making the entire system reflexive.
Day 2 Operations: Sustaining Infrastructure Beyond Provisioning
Many organizations still treat Infrastructure as Code as a Day 1 milestone - the successful deployment of cloud resources. But real operational maturity begins after go-live.
Cloud providers release updates. Modules evolve. APIs deprecate. Security advisories require urgent patching. Costs slowly creep upward. Without structured maintenance, even well-designed Terraform or OpenTofu stacks accumulate hidden risk.
Sustainable IaC adoption requires disciplined Day 2 operations across three critical areas.
Provider & Module Lifecycle: Preventing Version Debt
Every IaC stack depends on provider versions, reusable modules, and core runtime updates. When upgrades are postponed, organizations accumulate “version debt,” making future migrations risky and disruptive.
Mature teams implement:
-
Version pinning with controlled upgrade paths
-
Scheduled provider and module review cycles
-
Automated dependency scanning in CI pipelines
-
Testing upgrades in non-production workspaces before rollout
Incremental upgrades prevent infrastructure code from becoming legacy.
State File Governance: Protecting the Infrastructure “Brain”
The state file maps declared infrastructure to real-world resources. If lost, corrupted, or exposed, recovery becomes complex and sometimes costly.
Enterprise-grade governance includes:
-
Encrypted remote backends
-
Strict IAM access control
-
State locking to prevent concurrent corruption
-
Versioning and automated backup replication
Treating the state file as a regulated asset significantly reduces operational risk.
The Clean-Up Protocol: Eliminating Zombie Resources
Temporary environments enable experimentation - but without automated decommissioning, they accumulate and drive silent cost leakage.
A Clean-Up Protocol introduces:
-
Mandatory TTL (Time-to-Live) tagging for sandbox stacks
-
Scheduled scans for expired environments
-
Automated destroy workflows with approval gates
This ensures innovation does not translate into uncontrolled cloud sprawl.
Provisioning infrastructure is increasingly automated. Maintaining it securely, cost-efficiently, and without disruption is where true IaC maturity - and real MSP differentiation - emerges.
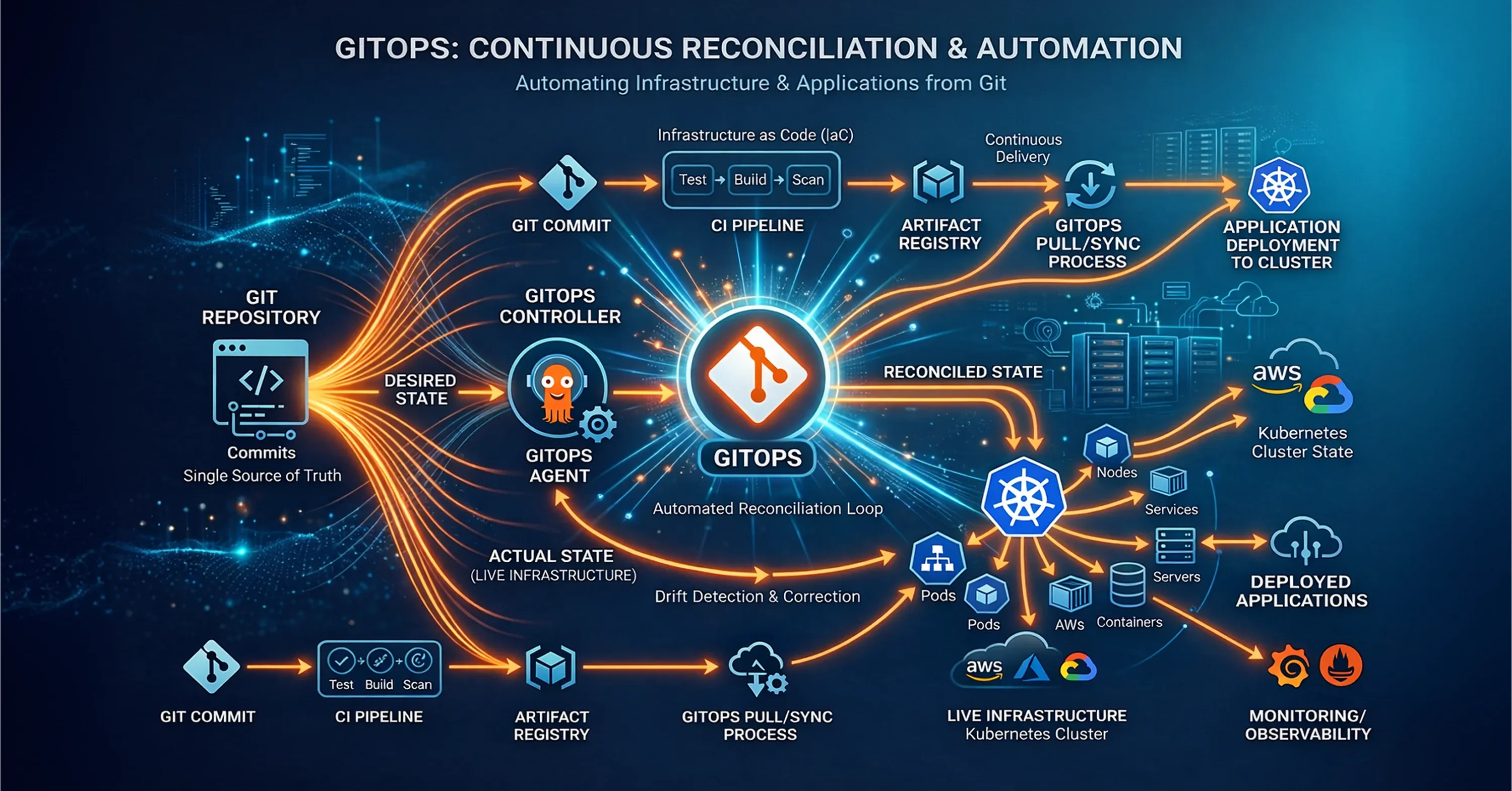
What Is Infrastructure as Code (IaC) and How Does It Automate Cloud Deployments?
Infrastructure as Code (IaC) automates cloud deployments by storing every resource - networks, servers, policies, and even dashboards - as version-controlled text files. When paired with GitOps agents, the code becomes the desired state, drift is detected and reconciled automatically, governance rules block risky changes before they ship, and disaster recovery can recreate entire regions in minutes. The result is a self-healing, cost-governed cloud that scales safely without manual console work.
Conclusion
IaC has evolved from simple provisioning scripts to a comprehensive framework that manages the full cloud lifecycle - drift remediation, cost governance, disaster recovery, and even self-healing. When combined with GitOps, Policy as Code, Observability as Code, and AI-powered refactoring, it forms the operational backbone for modern enterprises. Adopt these practices incrementally, measure drift debt and recovery times, and watch your cloud deployments become safer, faster, and far easier to manage.