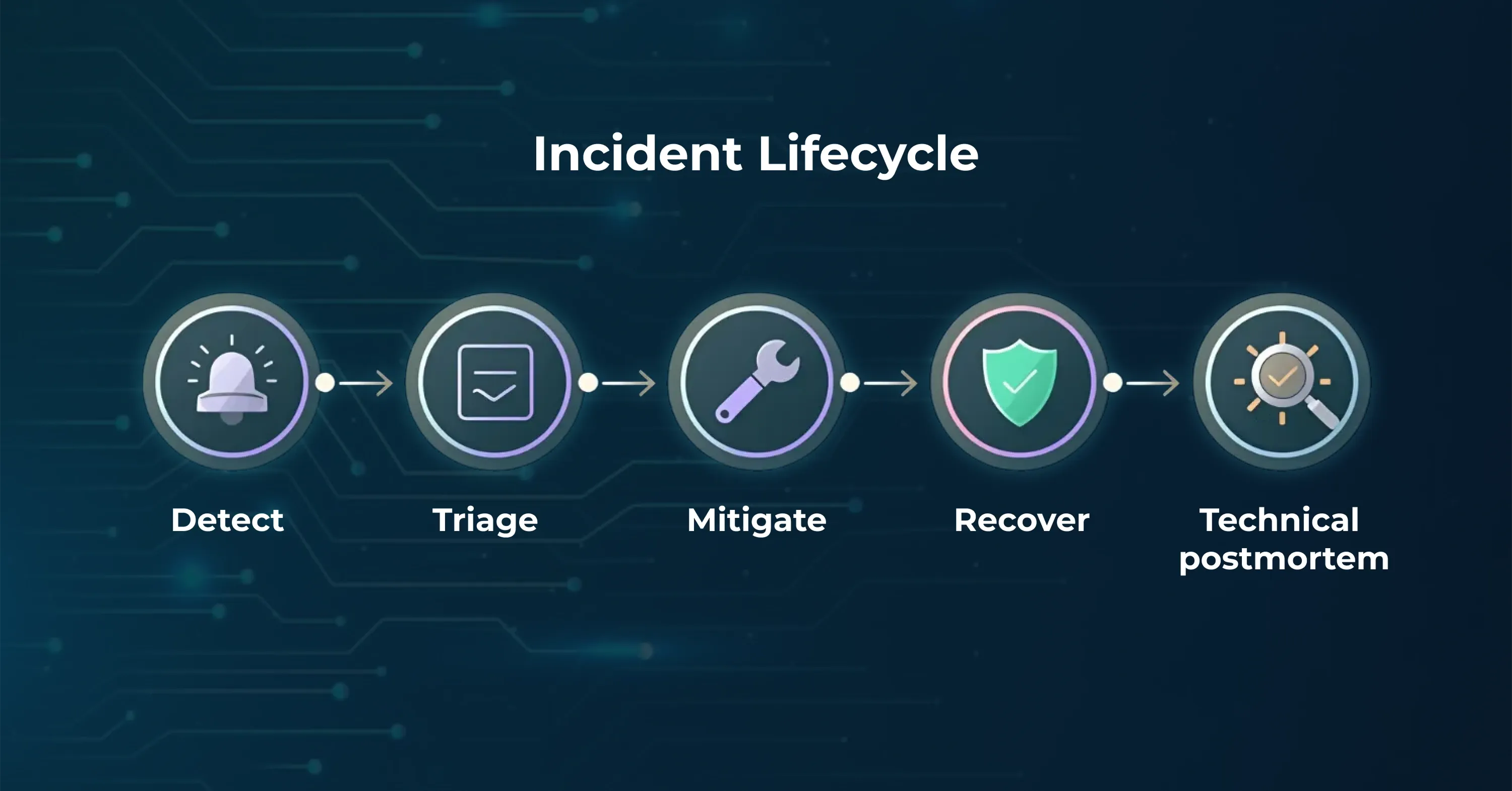
Pillar 3: Security Through DevSecOps and Regular Patching
Security lapses can be more damaging than downtime. DevSecOps threads safety checks throughout the delivery pipeline, catching misconfigurations and vulnerable libraries early.
Key practices
- Shift-left scanning of Infrastructure as Code templates
- Container image signing and vulnerability scanning
- Automated security tests in CI/CD
- Weekly patching cycles for OS and middleware
- Least-privilege IAM policies with short-lived tokens
Regulatory-heavy sectors such as HealthTech and FinTech see added peace of mind. Continuous compliance reports satisfy auditors without manual spreadsheet marathons.
Takeaway: A strong security posture is not a side project. It is an everyday discipline that guards the uptime you work so hard to protect. See how Information Security services can help you stay secure.
Continuous Delivery and IaC: The Engine Behind 24/7 Changes
High availability is pointless if code deploys are painful. CD pipelines built on IaC make shipping safe and boring.
From Commit to Production Without the Drama
- Developers push code to Git.
- CI runs unit, integration, and security tests.
- Approved builds trigger IaC tools like Terraform or AWS CloudFormation.
- Blue/green or canary releases shift traffic gradually, limiting blast radius.
- Rollbacks are a single command: the previous version still exists.
Because environments are defined in code, you can recreate them in minutes. This repeatability underpins 24/7 operations - no more weekend change freezes.
Final note: CD plus IaC turns infrastructure into a version-controlled asset, not a snowflake nobody dares to touch. To learn more, visit Cloud Services and DevOps.
Choosing a Partner for Cloud Support and Technical Support Services
Most organizations lack the bandwidth to staff round-the-clock rotations. External technical support services fill the gap.
Selection checklist
- Proven SRE track record with similar workloads
- Transparent SLAs: sub-5 minute response, defined escalation path
- Tooling compatibility with your stack
- Security certifications (ISO 27001, SOC 2)
- Cultural fit: responders communicate clearly, own problems through resolution
A leading provider of managed IT services, offering comprehensive solutions for infrastructure management, cloud computing, and cybersecurity, meets those benchmarks while letting your engineers focus on product features.
The right partner extends your team, not replaces it, keeping uptime high and stress low. To see how we help businesses across sectors, check our Industries expertise.
Conclusion
Downtime is inevitable - but chaos isn’t. Managed DevOps transforms those tense 2 a.m. alerts into calm, predictable recoveries. By combining continuous monitoring, rapid restoration, and built-in security, your infrastructure stops being a liability and becomes a launchpad for innovation.
This is the shift from firefighting to foresight - where every patch, backup, and deployment is automated, tested, and trusted. Your team can finally focus on building what matters while experts keep your cloud always-on, secure, and ready for whatever comes next.