Why moving all data to the cloud backfires
Cloud upload is cheap, but pulling data back costs real money and time. Egress fees average 5-10 cents per gigabyte. At terabyte scales, that dwarfs the GPU bill.
Problems with a cloud-only approach:
-
Petabyte datasets need weeks to copy via network or days with seeding drives
-
Daily syncs choke WAN links, competing with normal traffic
-
Regulatory constraints may forbid certain records from crossing borders
Bringing the AI to the data - through hybrid clouds or modern on-prem gear - avoids both shuttling delays and egress tolls.
Hybrid workflows look like this:
-
Keep raw logs and regulated PII on-prem
-
Ship only derived embeddings or anonymized features to the managed cloud
-
Send model updates back in bulk during low-traffic windows
This minimizes bandwidth and keeps governance officers happy. For granular best practices on balancing cloud and regulatory security, see Balancing Cloud Computing and Cloud Security: Best Practices.
Real-World Compliance Example
A pharmaceutical firm trains models on genomic data, which must remain in country. They installed a GPU pod in the same campus data hall and used the managed cloud only for model registry and global orchestration. Bandwidth dropped 87 %, and compliance audits passed without exception.
The financial lens: cloud outsourcing and managed hosting efficiencies
CFOs care about numbers first. Offloading infrastructure to specialized partners slashes both direct and hidden costs.
Direct savings:
Hidden savings:
-
Fewer outages mean less revenue leakage
-
Shorter procurement cycles increase feature velocity, boosting time to value
The managed hosting market is projected to jump from $140.11 billion in 2025 to $355.22 billion by 2030 at 20.45% CAGR as Mordor Intelligence notes. Boards see the trend and expect IT plans to follow it.
A simple back-of-the-napkin check: a 40-GPU cluster running 24 / 7 costs roughly $1.2 million in cloud fees per year. Owning and hosting the same hardware can hit $2 million once power, cooling, and staff are included. Mixed ownership, where busy-season spikes overflow into managed capacity, often lands 25-35 % cheaper than either extreme.
For additional strategies on optimizing spend and improving operational continuity, explore Cloud Support: How Managed DevOps Keeps Your Business Online 24/7.
Measured Cost Impact in Enterprise Environments
An insurance carrier performed a three-year total cost analysis. Hybrid managed hosting lowered net present cost by 28% compared with staying fully on public cloud and by 42% when compared with building a new data center wing.
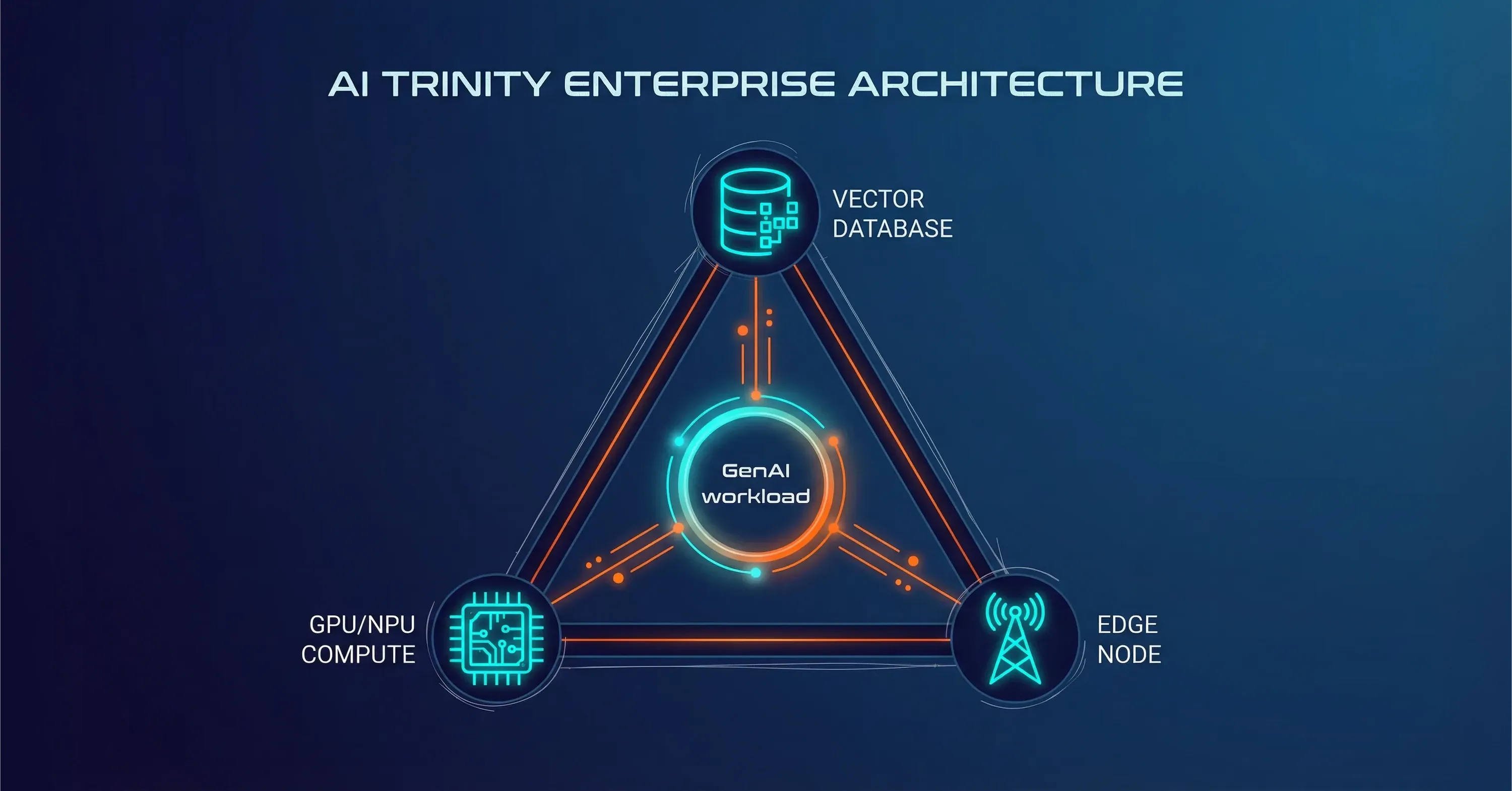
Managed cloud computing is not a silver bullet, yet it is the practical bridge between GenAI hype and the hardware reality. It lets you adopt the AI Trinity stack, place compute near data, and meet budget guardrails without rewriting every service.
What Is Managed Cloud Computing?
Managed cloud computing is the practice of delegating day-to-day operation, scaling, and security of cloud or hybrid infrastructure to a specialist provider. The model combines elastic resources, 24 / 7 monitoring, and FinOps insights so organizations can deploy resource-hungry GenAI workloads quickly while containing cost and risk.
Conclusion
GenAI success hinges on low latency, high concurrency, and predictable spend. Legacy stacks falter here. By adopting managed cloud computing, aligning with the AI Trinity, and keeping data where it makes sense, technology leaders gain the reliability users expect and the cost profile boards demand. For further insights on cloud transformation and modern best practices, read What Makes ‘Cloud Technologies’ Different in 2025?. The hype stays, yet the hardware finally keeps up.