Choosing between multi-zone and multi-region designs
Multi-zone design protects against localized failures inside a region, such as a power event or a network partition in one data center. Multi-region design protects against the loss of an entire region from correlated failures or large-scale natural events. The tradeoff is cost and complexity. Cross-region replication and consistency models get harder once a workload spans more than one geography.
Serverion cites JPMorgan Chase achieving 99.999% availability with a 28-second RTO across three AWS regions to meet financial-services compliance. Most workloads don't need that posture. Workload requirements should drive the topology.
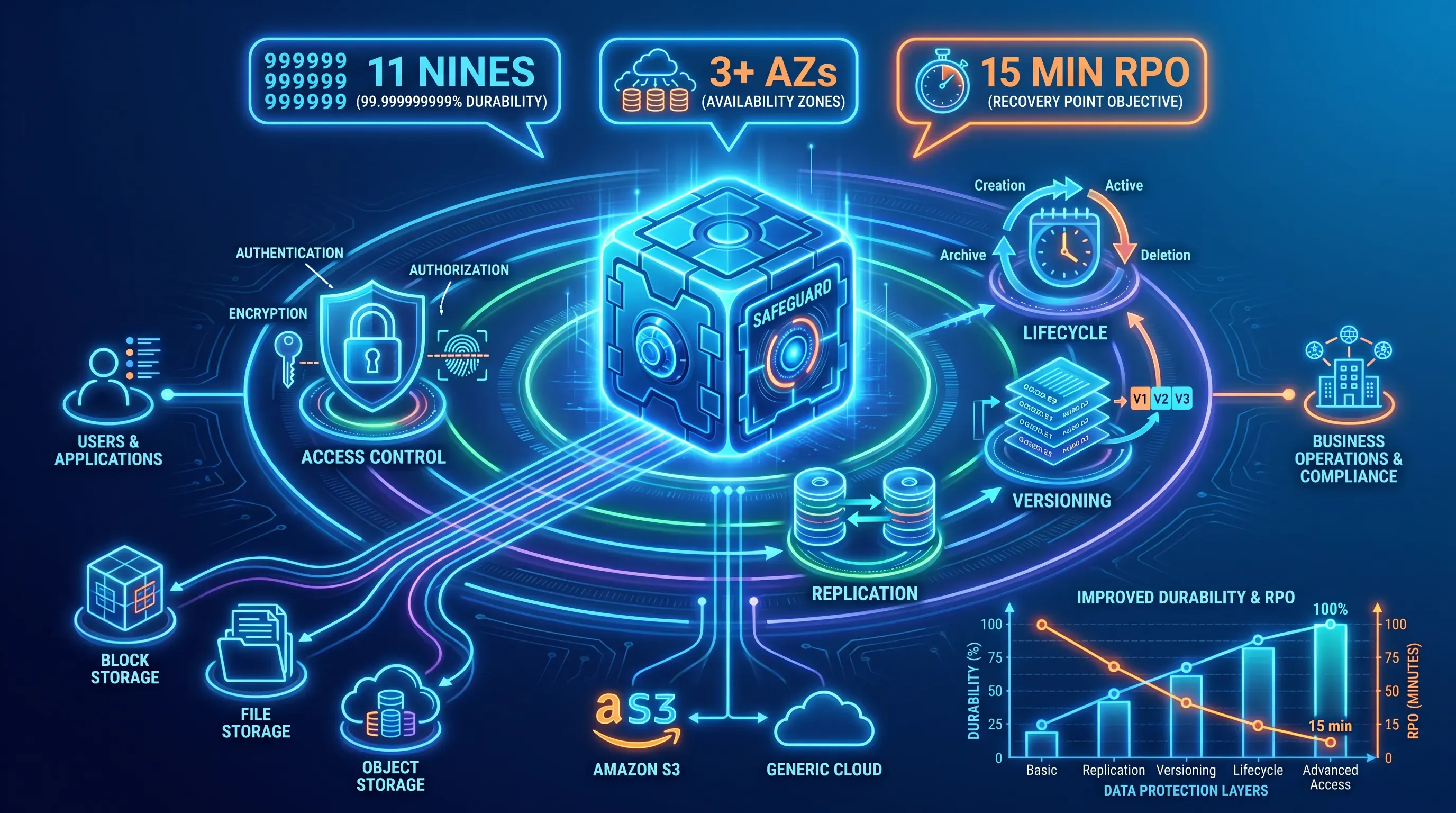
RTO and RPO drive redundancy choices
Recovery Time Objective (RTO) and Recovery Point Objective (RPO) translate business tolerance for downtime and data loss into specific architectural requirements.
Those two numbers determine the redundancy bill. A four-hour RTO with a daily RPO can live with nightly backups and warm standby. A one-minute RTO with near-zero RPO demands active-active replication and traffic management that can fail over in seconds. Skip the business conversation and the architecture either overspends or under-protects.
Environment segmentation reduces risk and complexity
Environment segmentation matters because it keeps experimental work and production traffic from touching the same blast radius. Dev and production should use separate networks and separate identities, and staging should be isolated to the same standard. Inside production, microsegmentation limits how far any single compromise can spread.
It is generally recommended to split production, staging, and pre-production environments across different VPCs. The boundary is operational as well as protective. A misbehaving load test in staging that cannot reach production cannot break production.
Segmentation also makes change management honest. When the only way to push something to production is through a controlled path, the path itself becomes the audit trail.
Separate environments protect production
Separate environments allow untested code a place to fail safely. Developers need an environment that looks like production without being production. Staging needs to mirror configuration and integration points closely enough that release candidates are tested under realistic conditions, yet it should remain walled off from real customers and real revenue.
State of Kubernetes Security report, summarized by StationX, found that 90% of organizations experienced at least one Kubernetes security incident in the past year, with 45% caused by misconfiguration. Environment parity catches those misconfigurations before they reach customers. The pattern is consistent: incidents that get caught in staging are footnotes, while the same incidents in production become postmortems.
Microsegmentation limits blast radius
By enforcing identity-based, workload-level access controls inside production, a compromised service cannot reach systems it has no business touching. Traditional perimeter segmentation stops at the edge. Microsegmentation enforces least privilege between every pair of workloads, regardless of where they sit on the network.
Pairing microsegmentation with strong identity controls turns lateral movement from a brisk walk into a series of locked doors. Each lock buys defenders time, which is the scarcest resource during an incident.
How infrastructure layers work together in production
The layers reinforce each other under real operational pressure. A traffic spike hits the load balancer, which spreads load across zones. Stateless compute scales out against the spike while databases serve from replicated block volumes. Object storage absorbs new artifacts. Segmentation keeps a failing microservice from poisoning its neighbors. Replicated state and explicit recovery targets decide what happens if a whole zone goes dark.
None of that is visible without observability. Logs, metrics, traces, and well-tuned alerts are how teams find out whether the design holds before customers do.
The practical test of a cloud architecture is what happens during a partial failure:
-
Does traffic shift automatically when a zone degrades, or does someone have to wake up?
-
Does autoscaling absorb the spike, or does it amplify the failure by overwhelming a downstream dependency?
-
Does segmentation contain a compromised pod, or does the blast wave reach the database?
-
Do the dashboards tell the on-call engineer what is happening within seconds, or within hours?
If those answers are uncertain, the architecture has not been tested. Resilience is the byproduct of layers that have been exercised together.
Next steps for strengthening your cloud infrastructure
Durable cloud environments result from architectural discipline across networking, compute, storage, redundancy, and segmentation. The practical next step is an honest assessment of where each of those layers stands today and where the gaps will hurt most when something fails.
ABS Technologies is a vendor-independent managed IT partner that helps organizations design and operate cloud infrastructure across all the layers covered in this article. Its Cloud Services and DevOps practice works across the major hyperscaler platforms, so recommendations follow the workload. The engagement model is built around running the underlying architecture so internal teams can focus on the products and services the business actually sells.
If you want a structured review of your current cloud footprint across network design, compute elasticity, storage policies, recovery objectives, and segmentation posture, request a free cloud infrastructure assessment from ABS Technologies and use the findings to prioritize the work that will matter most under pressure.