Overview
CI/CD pipeline automation is no longer an engineering preference. It is an operational requirement. This article is written for engineering leaders, DevOps teams, and CTOs who manage software delivery at scale and need to understand what drives that shift, where adoption breaks down, and what high-performing teams do differently.
Manual Pipelines Create Hidden Bottlenecks
Before making the case for automation, it helps to understand what happens without it. Manual or semi-manual delivery processes introduce friction at every stage of the software delivery lifecycle. A developer finishes a feature, then waits for someone to trigger a build. A tester runs validation scripts by hand. A release engineer copies configuration files across environments, hoping nothing drifts between staging and production.
These steps might feel manageable when a team ships once a month. They become unsustainable when the business expects weekly or daily releases.
The problems compound quickly:
-
Human error increases with every manual handoff, especially under time pressure.
-
Release schedules become unpredictable because each deployment depends on individual availability.
-
Configuration drift, where environments slowly diverge from each other, goes undetected until something breaks in production.
-
Engineering teams spend hours on repetitive tasks instead of building features that matter.
The cost is not just slower releases. It is lost confidence. When deployments feel risky, teams deploy less often. Feedback loops lengthen. Bugs hide longer. DORA research consistently shows that elite teams deploy on demand, multiple times per day, while low performers ship between once per month and once every six months. Manual processes are a primary reason teams stay stuck in that lower tier.
CI/CD Automation: How CI/CD Pipeline Automation Powers Modern Software Delivery explains in detail how organizations that automate move beyond these bottlenecks to balance speed with quality, and reduce the heavy costs and risks of manual processes.
When Manual Release Processes Become the Bottleneck
Consider a mid-size SaaS company that deploys a monolithic application through a series of shell scripts maintained by two senior engineers. When one goes on vacation, releases stall. When both are available, a single deployment still takes a full afternoon. The bottleneck is not the code. It is the process around the code.
This pattern is exactly what CI/CD pipeline automation is designed to eliminate.
Faster Cycles and Earlier Issue Detection
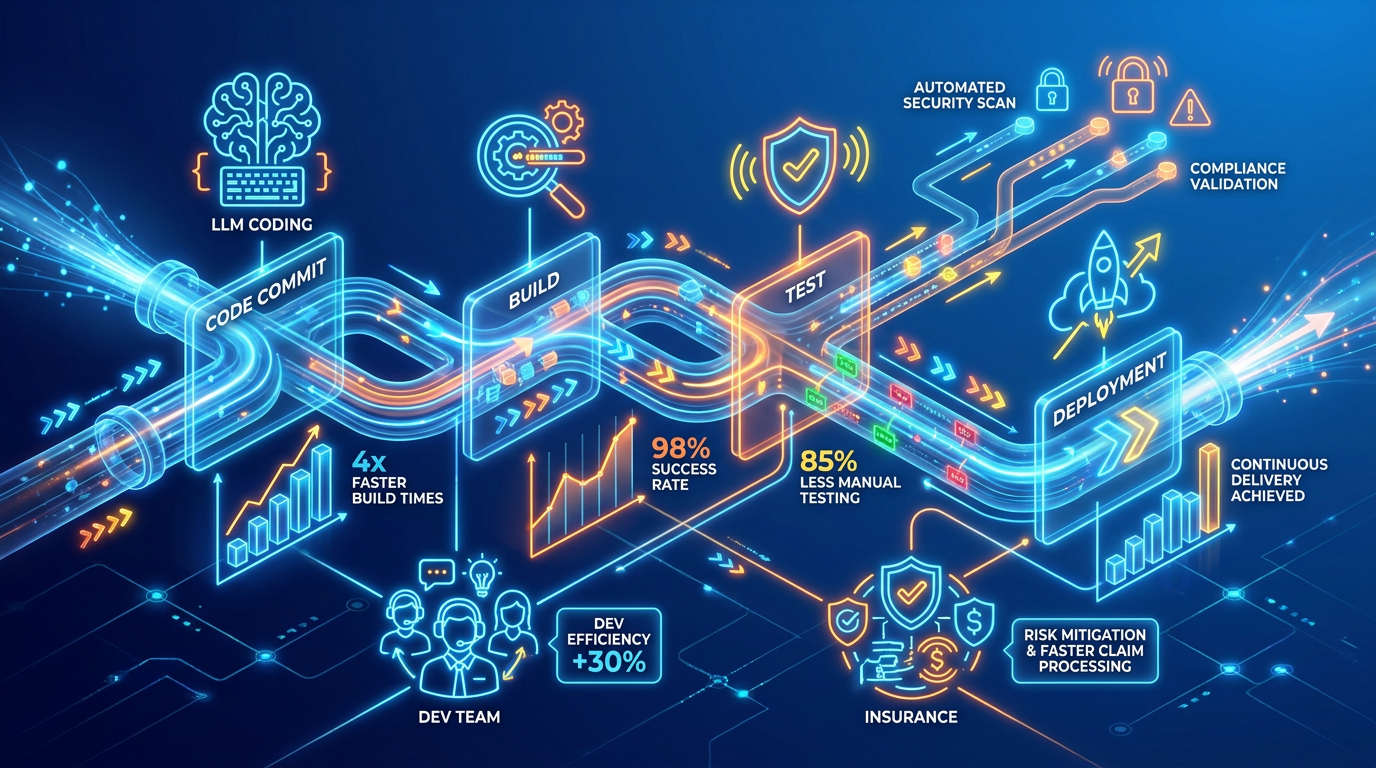
Automating the build, test, and deployment stages of a CI/CD pipeline does more than save time. It changes how quickly teams learn whether their code works. When every commit triggers an automated build and a suite of tests runs without human intervention, problems surface in minutes instead of days.
Continuous integration provides early visibility into bugs by catching issues the moment code is merged, not weeks later during a manual QA cycle. This early detection means fixes are smaller, faster, and far less expensive.
Automated testing is a major driver of this speed. Tests that once took hours or days to run manually now run in minutes, giving developers near-instant feedback on whether a change is safe to ship. Teams can measure this through metrics like test coverage percentage, execution time reduction, defect detection rate, and ROI based on time and cost savings.
The practical impact is measurable across four dimensions: delivery speed, defect cost, deployment stability, and recovery time.
-
Build-test-deploy cycles that previously took four to six hours can drop to under fifteen minutes.
-
Defects caught in CI cost roughly 10x less to fix than defects found in production, according to IBM Systems Sciences Institute research.
-
Change failure rate, the percentage of deployments that cause a production incident, drops below 15% for DORA elite performers. Manual pipelines typically run much higher.
When these cycles tighten, release confidence goes up. Teams that trust their pipeline deploy more often, and more frequent deployments reduce risk because each change is smaller and easier to roll back. Track rollback rate as a leading indicator: if you are rolling back more than 5% of deployments, your pipeline validation has gaps.
This is also where AI-generated code raises new stakes. With developers increasingly using LLM-assisted coding tools, the volume of code entering pipelines is growing faster than teams can manually review it. Automated scanning for known vulnerabilities, license compliance, and SBOM (Software Bill of Materials) generation becomes a pipeline requirement, not an optional stage. If your CI pipeline does not automatically validate what is in a build and where it came from, you are accepting supply chain risk by default.
For practical advice on using automated testing and cutting development time and costs, check out The Managed DevOps Cheat Sheet: how to cut App Development Time and Costs by 80% about devops technology.




