What You Will Learn
This article walks you through the core risks of tribal knowledge, the building blocks of Site Reliability Engineering (SRE) on a budget, and how to evaluate a managed IT provider that can guarantee a service level agreement strong enough for 2026-grade compliance. Along the way, you will see real-world examples from fintech portals that clear millions per hour, regional healthcare systems bound by PHIPA and HIPAA, and e-commerce brands that lose five figures for every minute their carts fail.
Before we dive deeper, pin this simple definition.
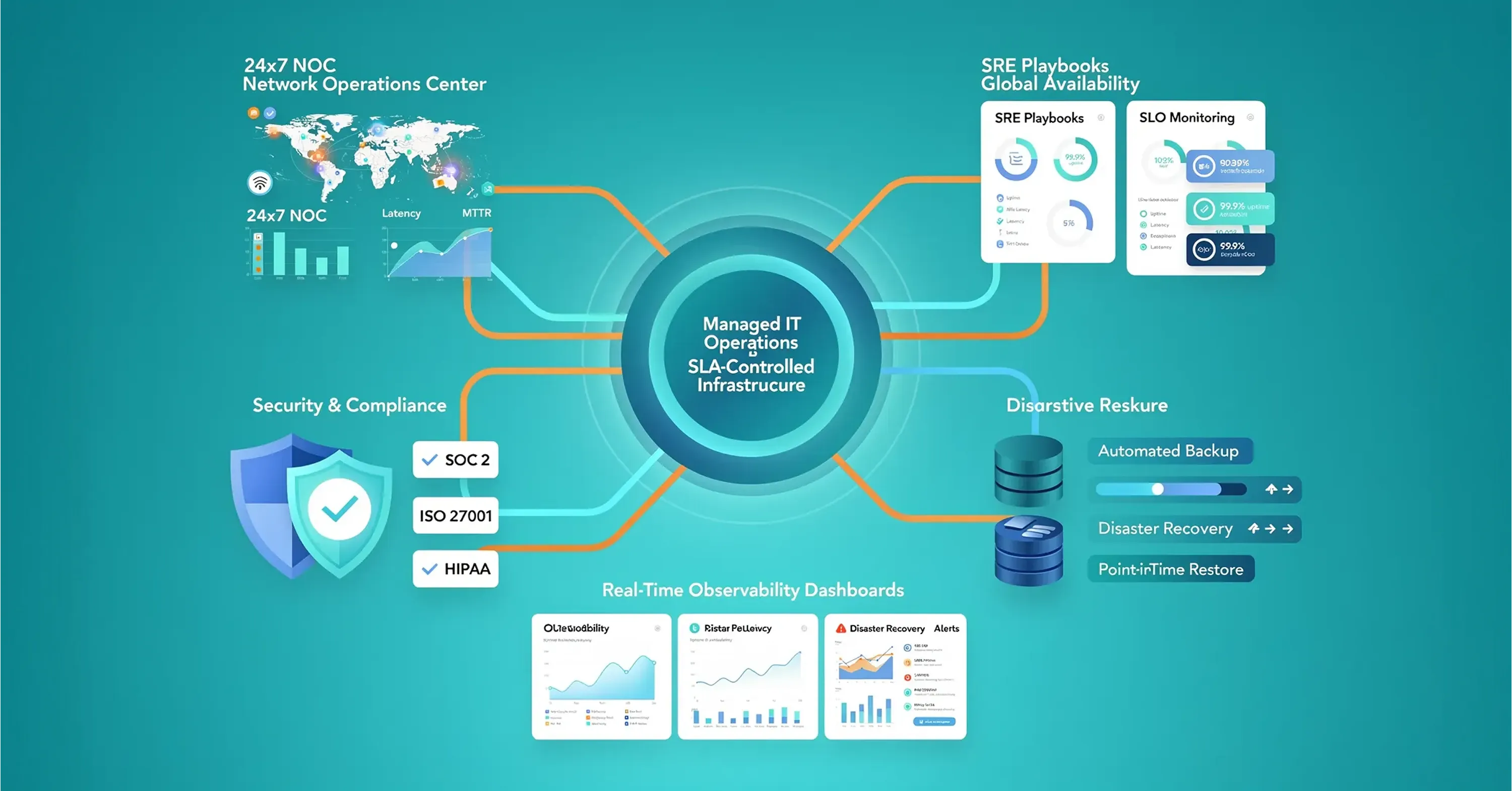
What Is a Managed IT Support Company?
A managed IT support company is a third-party organization that assumes day-to-day responsibility for a customer’s infrastructure, cloud environments, and cybersecurity, delivering documented, automated, and round-the-clock operations under a commercial service level agreement that guarantees specified uptime, response times, and security controls.
The Hidden Cost of Tribal Knowledge
The problem rarely begins with technology. It starts with human bottlenecks. One sysadmin tweaks Terraform files at 2 a.m., no one documents why, and the whole stack becomes opaque.
-
Failed handovers delay recovery during incidents
-
Vacation overlap means no one can deploy a hotfix
-
Compliance audits stall because evidence lives in personal laptops
In industries where every 15-minute outage erases six-figure revenue, that is unacceptable. CEOs often assume redundancy at the cloud layer covers them, but resilience is a process, not a zone-redundant checkbox.
Tribal knowledge also blocks innovation. New hires waste weeks reverse-engineering bash scripts rather than shipping features. The cost in developer morale is subtle yet real.
The obvious fix is process documentation, but writing docs is no one’s day job. That is why more firms shift to external partners that treat documentation as a deliverable, not a nice-to-have.
This brings us straight to how an external team can institutionalize what is currently stuck in one engineer’s head.
How Tribal Knowledge Caused a $420,000 Outage
A Bahrain-based payments gateway handled 14 million transactions per month. Only the original architect understood the Kubernetes ingress rules. During Ramadan peak traffic, he was in London. A mis-typed Helm update blocked the public API for 19 minutes, costing USD 420,000 in lost fees. After onboarding a managed IT support company with mandatory run-books stored in Git, any engineer can now roll back in under five minutes.
The stage is set to explore what you gain when you outsource this operational muscle.